Characterizing Risks with Probabilities
The best way to understand project risk is to characterize it by describing the range of possible outcomes, estimating when they could occur (risk timing), and assessing probabilities. If relevant data are available (e.g., as might be the case for system failure probabilities for evaluating reliability maintenance projects), probabilities for characterizing risks can be derived using statistical analysis. In the absence of such data, probabilities must still be assigned and it makes sense to do so directly based on expert judgment.
Although quantifying risks requires more inputs to describe proposed projects, note that the additional inputs need not be very complex. If some aspect of a project's performance is uncertain, instead of obtaining only a middle-value, point estimate, get a range of possible values (e.g., a 90% confidence interval) as well as a mean or most-likely value. (As I described in Part 1: Introduction to biases, techniques should be used to guard against overly narrow ranges caused by overconfidence.) With practice, it takes no more time to specify a range than it does to generate a single point estimate. The necessary probabilities can be roughly estimated from the range and a mean or most-likely value.
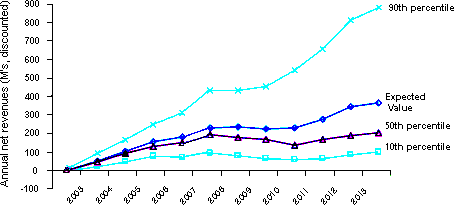
Once probabilities have been assigned to important risks, those probabilities can be propagated through the value model (described in Part 3: Lack of the right metrics) to derive the uncertainty over the various benefits and total value of the project. This can be done using Monte Carlo analysis or event trees. The probabilities can be displayed graphically to show how uncertainty evolves over time, see Figure 7. The amount of uncertainty caused by project risks and the specific project benefits that are impacted may be used to better estimate what hurdle rates should be used and the types of benefits to which they should be applied.
Figure 7: Evolution of risk values over time
|